引言
隨著數(shù)字內(nèi)容產(chǎn)業(yè)的蓬勃發(fā)展,數(shù)據(jù)量呈現(xiàn)指數(shù)級(jí)增長(zhǎng)。傳統(tǒng)的MySQL數(shù)據(jù)庫(kù)在處理海量歷史數(shù)據(jù)和復(fù)雜分析查詢時(shí)面臨性能瓶頸。本文將介紹如何利用云原生數(shù)據(jù)倉(cāng)庫(kù)Databend構(gòu)建MySQL歸檔分析與數(shù)字內(nèi)容制作服務(wù),實(shí)現(xiàn)數(shù)據(jù)存儲(chǔ)與計(jì)算的高效分離。
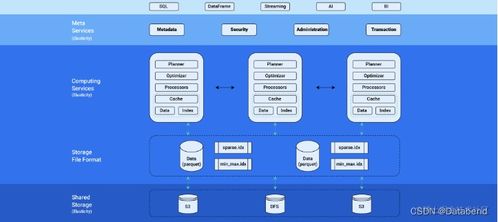
Databend架構(gòu)優(yōu)勢(shì)
Databend作為新一代云原生數(shù)據(jù)倉(cāng)庫(kù),具備以下核心優(yōu)勢(shì):
- 彈性擴(kuò)展能力:基于云原生架構(gòu),支持按需擴(kuò)縮容,完美應(yīng)對(duì)數(shù)字內(nèi)容制作中突發(fā)流量需求
- 極致性能表現(xiàn):采用列式存儲(chǔ)和向量化執(zhí)行引擎,在復(fù)雜分析查詢場(chǎng)景下比MySQL提升數(shù)十倍性能
- 存儲(chǔ)計(jì)算分離:實(shí)現(xiàn)數(shù)據(jù)存儲(chǔ)與計(jì)算的完全解耦,大幅降低運(yùn)維復(fù)雜度和成本
- 標(biāo)準(zhǔn)SQL兼容:完全兼容MySQL協(xié)議,遷移成本極低
系統(tǒng)架構(gòu)設(shè)計(jì)
數(shù)據(jù)流架構(gòu)
MySQL在線層 → 數(shù)據(jù)同步層 → Databend分析層 → 應(yīng)用服務(wù)層
核心組件
- 數(shù)據(jù)采集模塊
- 基于CDC技術(shù)實(shí)時(shí)捕獲MySQL變更數(shù)據(jù)
- 支持全量和增量數(shù)據(jù)同步
- 數(shù)據(jù)格式轉(zhuǎn)換與標(biāo)準(zhǔn)化處理
- Databend存儲(chǔ)集群
- 構(gòu)建多租戶數(shù)據(jù)倉(cāng)庫(kù)環(huán)境
- 實(shí)現(xiàn)數(shù)據(jù)分層存儲(chǔ)(熱數(shù)據(jù)、溫?cái)?shù)據(jù)、冷數(shù)據(jù))
- 支持?jǐn)?shù)據(jù)壓縮與加密
- 分析計(jì)算引擎
- 提供OLAP查詢服務(wù)
- 支持復(fù)雜多維度分析
- 集成機(jī)器學(xué)習(xí)算法庫(kù)
- 數(shù)字內(nèi)容制作服務(wù)
- 基于分析結(jié)果生成個(gè)性化內(nèi)容
- 自動(dòng)化內(nèi)容生產(chǎn)流水線
- 多格式內(nèi)容輸出支持
實(shí)施步驟
第一階段:環(huán)境準(zhǔn)備與數(shù)據(jù)遷移
- Databend集群部署
- 選擇云服務(wù)商(AWS/Azure/GCP)
- 配置計(jì)算節(jié)點(diǎn)和存儲(chǔ)資源
- 設(shè)置網(wǎng)絡(luò)連接與安全策略
- 數(shù)據(jù)同步管道搭建
- 部署Debezium或Canal實(shí)現(xiàn)MySQL CDC
- 配置數(shù)據(jù)轉(zhuǎn)換規(guī)則
- 建立數(shù)據(jù)質(zhì)量監(jiān)控機(jī)制
第二階段:分析服務(wù)開(kāi)發(fā)
- 數(shù)據(jù)建模
- 設(shè)計(jì)星型/雪花數(shù)據(jù)模型
- 建立維度表和事實(shí)表
- 優(yōu)化分區(qū)策略和索引
- 查詢服務(wù)封裝
- 開(kāi)發(fā)RESTful API接口
- 實(shí)現(xiàn)查詢緩存機(jī)制
- 構(gòu)建數(shù)據(jù)權(quán)限管理體系
第三階段:數(shù)字內(nèi)容制作集成
- 內(nèi)容生成引擎
- 基于分析結(jié)果觸發(fā)內(nèi)容制作
- 集成模板引擎(Jinja2/Thymeleaf)
- 支持多媒體內(nèi)容合成
- 工作流編排
- 使用Airflow或Dagster編排任務(wù)
- 實(shí)現(xiàn)內(nèi)容質(zhì)量自動(dòng)檢測(cè)
- 建立發(fā)布審核流程
應(yīng)用場(chǎng)景案例
場(chǎng)景一:用戶行為分析報(bào)告
通過(guò)分析用戶在數(shù)字平臺(tái)上的歷史行為數(shù)據(jù),自動(dòng)生成個(gè)性化行為分析報(bào)告,包含:
- 使用頻次統(tǒng)計(jì)
- 偏好內(nèi)容分析
- 活躍時(shí)段分布
- 行為趨勢(shì)預(yù)測(cè)
場(chǎng)景二:內(nèi)容生產(chǎn)優(yōu)化
基于歷史內(nèi)容表現(xiàn)數(shù)據(jù),為內(nèi)容制作團(tuán)隊(duì)提供:
- 熱門(mén)主題推薦
- 最佳發(fā)布時(shí)間建議
- 內(nèi)容格式優(yōu)化指導(dǎo)
- 受眾群體畫(huà)像分析
場(chǎng)景三:運(yùn)營(yíng)數(shù)據(jù)大屏
構(gòu)建實(shí)時(shí)數(shù)據(jù)大屏,展示:
- 內(nèi)容訪問(wèn)實(shí)時(shí)監(jiān)控
- 用戶增長(zhǎng)趨勢(shì)
- 業(yè)務(wù)關(guān)鍵指標(biāo)
- 異常預(yù)警信息
性能優(yōu)化策略
查詢性能優(yōu)化
- 數(shù)據(jù)分區(qū)策略:按時(shí)間、業(yè)務(wù)類(lèi)型等維度分區(qū)
- 索引優(yōu)化:針對(duì)高頻查詢字段建立合適索引
- 緩存機(jī)制:多級(jí)緩存(查詢結(jié)果緩存、元數(shù)據(jù)緩存)
- 查詢重寫(xiě):優(yōu)化復(fù)雜查詢的執(zhí)行計(jì)劃
成本控制
- 存儲(chǔ)分層:根據(jù)數(shù)據(jù)訪問(wèn)頻率采用不同存儲(chǔ)介質(zhì)
- 計(jì)算資源調(diào)度:按需啟停計(jì)算節(jié)點(diǎn)
- 數(shù)據(jù)生命周期管理:自動(dòng)歸檔歷史數(shù)據(jù)
- 監(jiān)控告警:實(shí)時(shí)監(jiān)控資源使用情況
技術(shù)挑戰(zhàn)與解決方案
數(shù)據(jù)一致性保證
挑戰(zhàn):MySQL與Databend之間的數(shù)據(jù)延遲可能導(dǎo)致分析結(jié)果不一致
解決方案:
- 實(shí)現(xiàn)最終一致性保證
- 建立數(shù)據(jù)版本管理機(jī)制
- 提供數(shù)據(jù)延遲監(jiān)控告警
系統(tǒng)可用性
挑戰(zhàn):?jiǎn)吸c(diǎn)故障可能導(dǎo)致服務(wù)中斷
解決方案:
- 構(gòu)建多可用區(qū)部署架構(gòu)
- 實(shí)現(xiàn)故障自動(dòng)轉(zhuǎn)移
- 建立完善的備份恢復(fù)機(jī)制
總結(jié)與展望
基于Databend構(gòu)建的MySQL歸檔分析與數(shù)字內(nèi)容制作服務(wù),成功解決了傳統(tǒng)架構(gòu)在數(shù)據(jù)處理能力上的局限性。該方案不僅提供了強(qiáng)大的數(shù)據(jù)分析能力,還為數(shù)字內(nèi)容制作提供了數(shù)據(jù)驅(qū)動(dòng)的智能支持。
我們將繼續(xù)探索:
- 集成更多AI能力提升內(nèi)容生成質(zhì)量
- 優(yōu)化實(shí)時(shí)分析處理能力
- 擴(kuò)展更多數(shù)字內(nèi)容類(lèi)型支持
- 深化數(shù)據(jù)安全與隱私保護(hù)
通過(guò)持續(xù)的技術(shù)創(chuàng)新和業(yè)務(wù)實(shí)踐,我們相信基于云原生數(shù)倉(cāng)的解決方案將為數(shù)字內(nèi)容產(chǎn)業(yè)帶來(lái)更大的價(jià)值突破。